Изкуственият интелект става все по-съвършен и е все по-трудно да разграничим истинския образ от фалшивия.
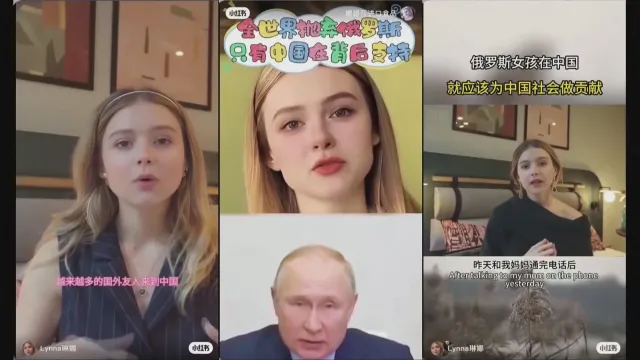
Пример за това са дигиталните двойници на украинката Олга Лойек, направени с изкуствен интелект.
Той я показва като рускинята Наташа, която говори свободно китайски. В манипулираните видеа тя благодари на Китай за подкрепата към Русия.
Фалшивите акаунти на Олга са следвани от хиляди души в Китай.
„За да създам свой собствен дигитален човек, просто трябва да заснема 30-минутен видеоклип на себе си и след като го завърша, преработвам видеоклипа. Разбира се, той изглежда много реален и ако промените езика, единственото нещо, което трябва да коригирате, е синхронизирането на устните“, казва Джим Чай, изпълнителен директор на технологична компания.
„Не харесвам това, че някой може да използва лицето на някой друг, за да го накара да каже каквото си поиска“, коментира украинската студентка Олга Лойек.
Свързана новина

И от видеата – към снимките, в които се намесва изкуственият интелект. Според експерти става и ще става все по-трудно да се направи разлика между изкуствено генерираните изображения и истинските снимки. За да не сме заблудени, трябва да търсим фините детайли.
„Продължава да е голяма трудност за алгоритмите да създават достатъчно реалистично човешкото лице и човешките ръце по някакъв начин. В началото всички се смеехме, че генеративните модели създават ръце с по 6 пръста, с по 4 пръста. Това вече се случва доста по-рядко, но те много често са в неестествени позиции“, обяснява Георги Караманев, създател на сайта „Дигитални истории“.
По думите му човек инстинктивно може да забележи, че нещо не е както трябва, защото генеративните модели допускат някакви грешки във фона.
Свързана новина

„Ако се вгледаме например в по-малките лица на фон, много често там има някакви грешки и неточности... Ако нещо е прекалено съвършено, ако кожата е напълно равна, лъскава на човека – това също е знак, че може да е генерирано изображение. Още едно нещо, по което често може да различим, е, ако загледаме текстовете. На алгоритмите все още е трудно да сложат текст, който да е достатъчно логичен в рамките на изображението“, допълва Караманев.
През 2019 г. ABC посочи най-честите грешки, допускани от AI алгоритми – размазани петна, хаотични фонове, изкривени очила, неправилни аксесоари, асиметрии.

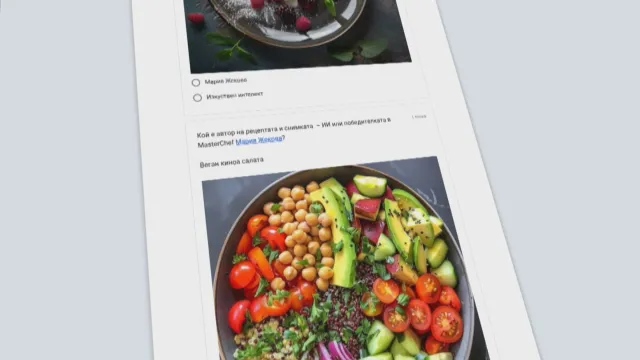
Да разпознаят изображения, създадени с изкуствен интелект, провокира читателите на сайта „Дигитални истории“ на Георги Караманев. В експеримента се включват 1800 души.
„Хората се оказаха неспособни да различат изображения в стила на Йеронимус Бош. Той е толкова характерен, толкова познат художник. Но на едно от двете изображения 80% от хората бяха предположили, че това е художникът, а се оказа, че е алгоритъмът. Подобно беше и с готварските рецепти. На няколко от рецептите хората се объркаха значително - 3/4 от хората бяха сбъркали част от рецептите, не бяха разпознали кое е снимка и кое е картинка, генерирана от изкуствен интелект“, коментира Караманев.
Въпреки усилията, социалните мрежи не успяват да се справят с контрола върху фалшивата информация, генерирана от изкуствения интелект. Едно е сигурно - проблемите с регулацията на това съдържание остават нерешени.
„Това вероятно е проблем номер едно за киберсигурността, за технологиите и вероятно за правителствата през следващото десетилетие“, казва Рич Търнър, президент на фирма за киберсигурност.

„Всяко следващо поколение изкуствен интелект, който генерира текст и изображения, става все по-добро и все по-неразличимо в конкретни задачи, но наистина чакам с нетърпение момента, в който това ще се случи и с генерирането на видеото. Това ще е голяма стъпка, защото наистина е трудна задача.... Само че в света на технологиите е много лесно да сбъркаш с прогнозите си. Неща, които ни изглеждат много близки, че ще се случат много скоро, се оказват невъзможни и обратното“, допълва Георги Караманев.
В момента критичното мислене остава най-надеждният начин за разпознаване на истинското сред фалшивото.